
“Shipping AI Without Testing? You Can’t Fix What You Don’t Measure.”
- Jassimran Kaur
- Apr 14, 2025
- 3 min read

As of early 2025, ~78% of organizations report using generative AI in at least one business function, marking a significant increase from previous years. [1] [2]. By 2025, it’s projected that 750 million apps will be using LLMs in some form. But here’s the kicker: Only 1% feel confident about what it’s actually doing. [3]
This raises the core question:
“If everyone is using LLMs, why is almost no one making sure they actually work?”
![Risks of not testing your LLM based applications.[3]](https://static.wixstatic.com/media/b51375_a4e9196a3e3945a99633468a903e8682~mv2.png/v1/fill/w_927,h_536,al_c,q_90,enc_avif,quality_auto/b51375_a4e9196a3e3945a99633468a903e8682~mv2.png)
Risks of not testing your LLM based applications.[3]
⚠️ What happens When You Don't Evaluate Your LLM Apps
When outputs start going off-script, trust erodes fast. Poorly evaluated systems can lead to:
Broken user experiences
Brand damage from hallucinated or biased outputs
Security and compliance nightmares, lawsuits.
High churn (because users won’t come back if the answers suck)
This isn’t a hypothetical future. It’s already happening. Despite this, LLM evaluation often remains an afterthought.
❓So, Why aren't we Evaluating?
Despite the high adoption rates of generative AI, just 1% feel confident in their GenAI maturity.[7] Here are the real reasons LLM evaluation keeps getting ignored 👇
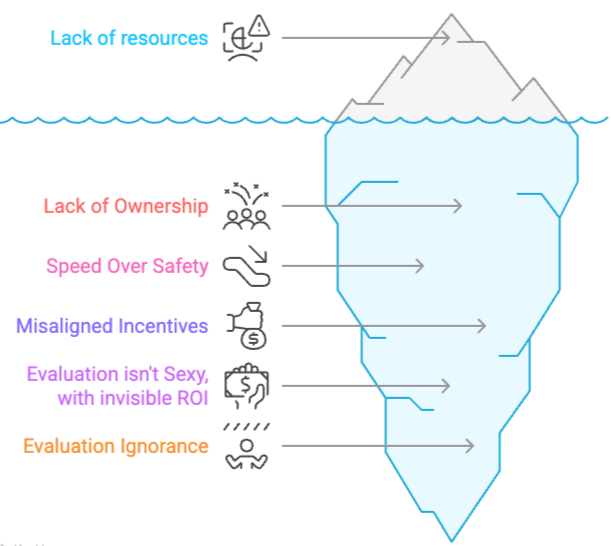
No One Owns It: Evaluation doesn’t neatly fall into product, data science, or QA.
PMs assume the AI team is doing it
AI folks think product should define success
QA treats LLMs like normal software (they’re not)
So it becomes everyone’s job—and no one’s responsibility.
Metrics ≠ Meaning: Automated proxy metrics like Truthfulness, helpfulness are overused because they’re easy—not because they’re right. Most don’t reflect what success actually looks like in your application.
Evaluation Isn’t “Sexy” Yet: Let’s be honest, in the GenAI world, people want to build Autonomous Agents, not dashboards.
AI Agents are sexy. Evaluation is not.
Evals are seen as grunt work, not innovation.
Many AI teams get social capital from demos, not from saying “hey, I caught a hallucination!”
"Evaluation is invisible work. It’s critical—but thankless. And in a hype-driven field, teams prioritize what’s flashy over what’s foundational."
Lack of Evaluation Literacy + Misaligned Incentives: Teams just don’t know where to start. Setting up robust evaluation pipelines takes time, expertise, and coordination. Also, none of these deliver short-term ROI. Evaluation feels ambiguous and disconnected from business ROI. Teams don’t lack resources—they lack clarity and urgency. So it gets pushed to “later,” right until things go wrong in production. [8]
🚀 Speed vs Safety: AI teams are under pressure to ship prototypes fast, there's usually no evaluation in the development lifecycle, and once it's “working” in a demo, it’s considered “good enough”—until it isn’t. We ship LLM features like we’re shipping buttons. But LLMs aren’t deterministic, and lack of evals means issues only show up in production. I am not saying don't ship fast, but as soon as an alpha version is out, next step is setting up Evals, Traces, building Golden dataset (you start wth 1 data point), no prompt change happens without the regression testing as part of CI/CD. Start with healthy practices early on, when stakes are low.
✅ Solution: Where should you start?
Evaluation doesn’t need to be perfect. It needs to be practical. Here’s your starter playbook:
Assign ownership — someone needs to drive it, ideally a PM, who needs to add AI quality as KPI to, and assign tasks to individuals.
Start collecting feedback from Day 0: Feedback is very hard to get, make it ridiculously easy for your users to give you feedback. Doing it early on, helps you spot issues sooner.
Start simple. 👍 👎 + optional comment is all you need
Most LLM Evaluation platforms facilitate this.
Langfuse - User feedback collection
Humanloop - Capture User feedback
Arize.AI - Collect Human Feedback
Involve Domain Experts Early (Yes, Real Humans): Even the smartest eval tool won’t know what “correct” looks like in your industry. Domain experts do —but they probably hate extra tools. Make feedback collection frictionless inside the app i.e. in their workflows, not in spreadsheets
Establishing Clear Evaluation Criteria: While working with experts, try to develop metrics that they care about. Just start with one metric - “What is the most fundamental task that your application should never fail at.”
Start building Golden Dataset for Continuous Monitoring: LLMs drift. Your users evolve. Prompts change. Model updates sneak in. Start building a “golden dataset” of examples and evolve it over time. Run regressions on each release. No surprises. Use LLM-as-a-Judge to help you here.

🧠 Thought to Leave You With
If you're building with LLMs but not evaluating them, ask yourself:
How do you know your system is working?
What needs to be improved in the system?
Why should anyone trust your product?
LLM evals aren't “nice to have.” They’re your safety net
Need help to get started, Drop me a note—we help teams get this right.


Comments